Application Framework User Interface
To use the Applications Framework feature, in the Cisco DCNM home page's left pane, click Applications.
The Applications window displays the following tabs:
-
Catalog—This tab lists the applications that are used by Cisco DCNM. These applications for performing various functions within Cisco DCNM. For more information, see Catalog.
-
Compute—This tab displays the existing compute nodes. The tab shows nodes that are part of the hosting infrastructure. The uptime indicates how long they have been part of the infrastructure. In a High Availability (HA) setup, both the active and the standby nodes appear as joined. For more information, see Compute.

Note
In the cluster mode, the Cisco DCNM servers will not appear under the Compute tab.
-
Preferences—This tab is relevant to the cluster mode of deployment, where the application instances are placed. This tab enables you to compute the cluster connectivity and configure the Cluster Connectivity preferences. For more information, see Preferences.
Cisco DCNM uses the following applications:
-
Kibana: This is an open-source data-visualization plug-in for Elasticsearch, which provides visualization capabilities. Cisco DCNM uses the Kibana application for the Media Controller, and Endpoint Locator.
-
San Insight Pipeline Collector(1.0)
-
SAN Insight Post Processor(1.0)
-
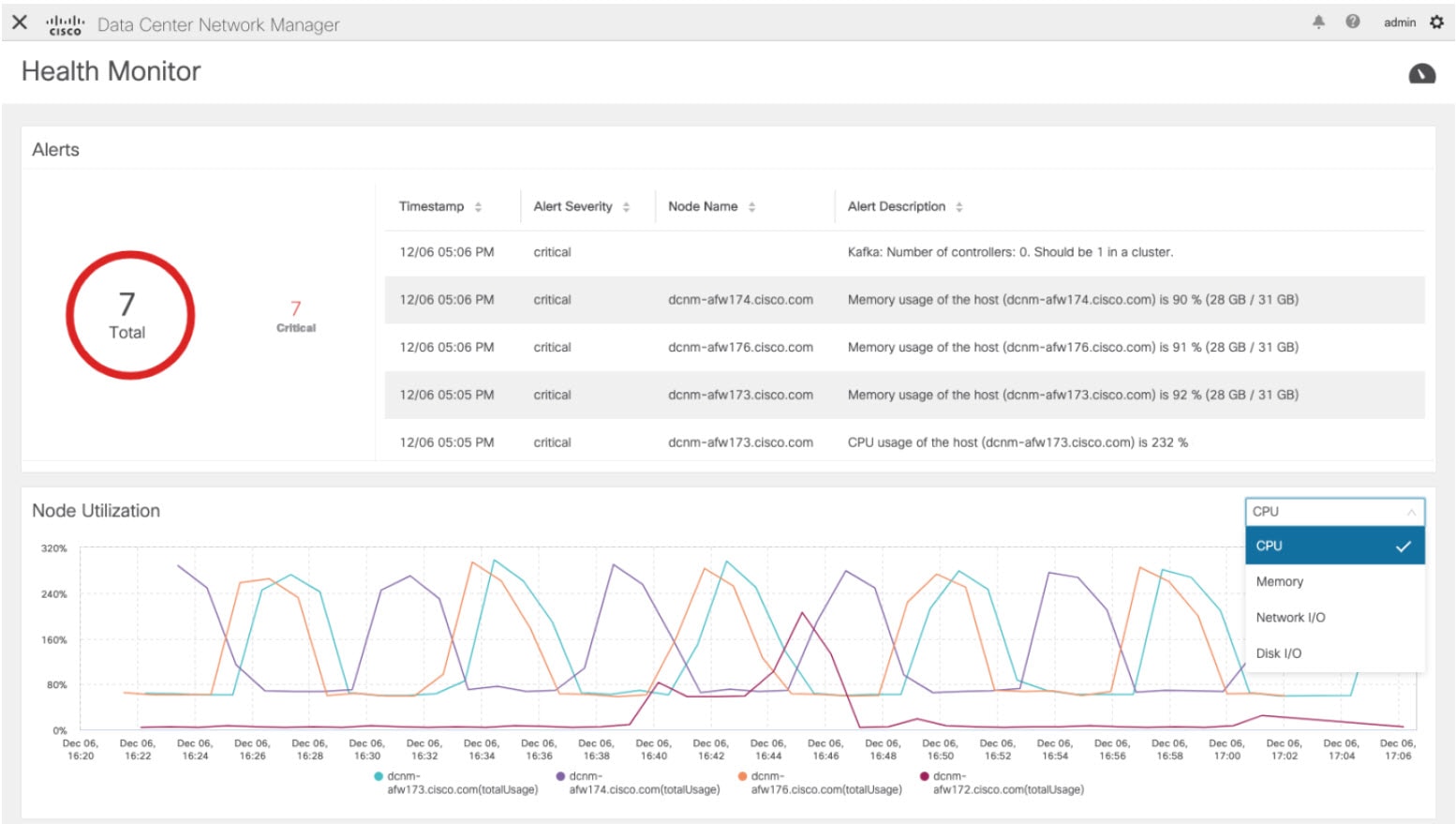
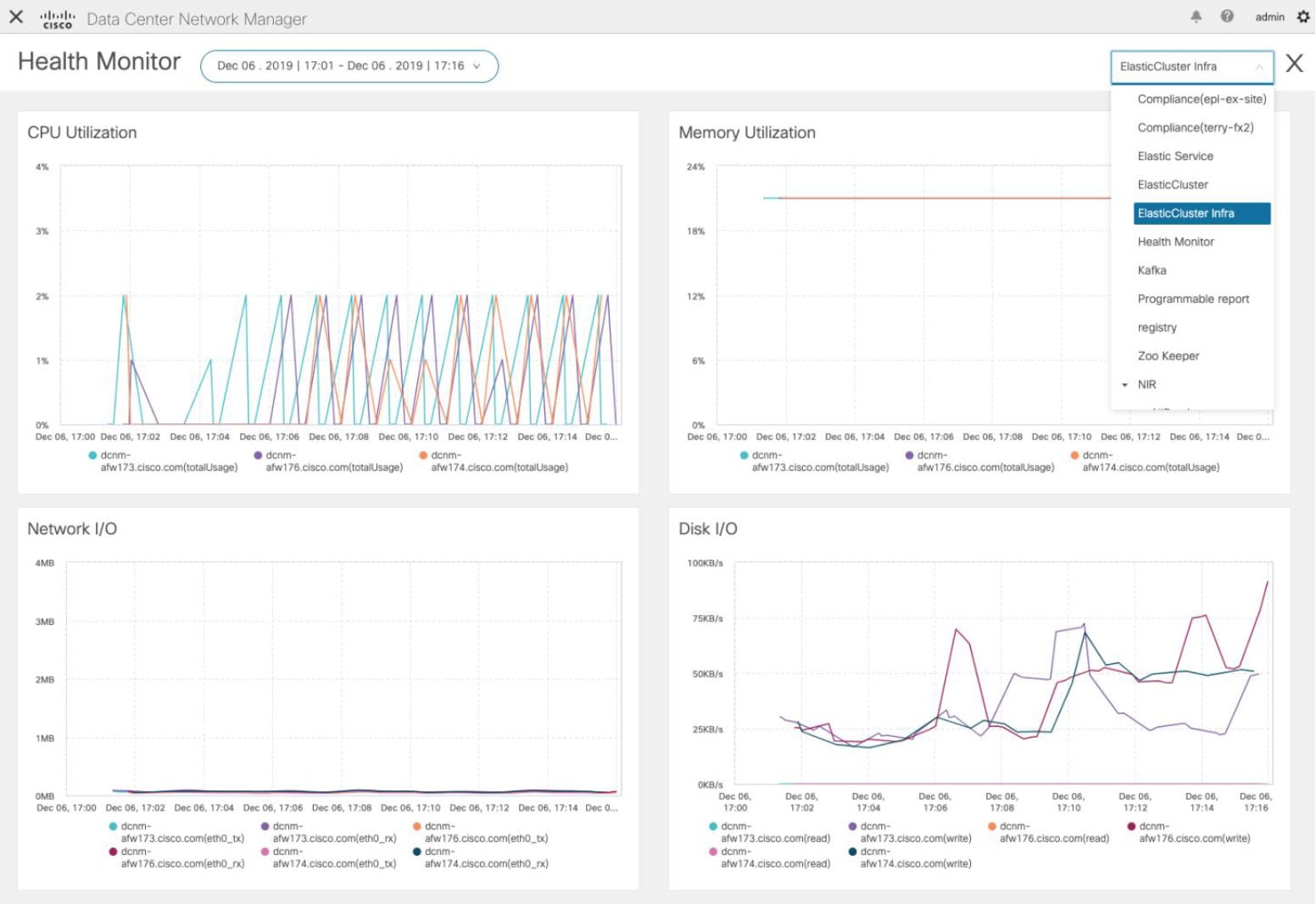
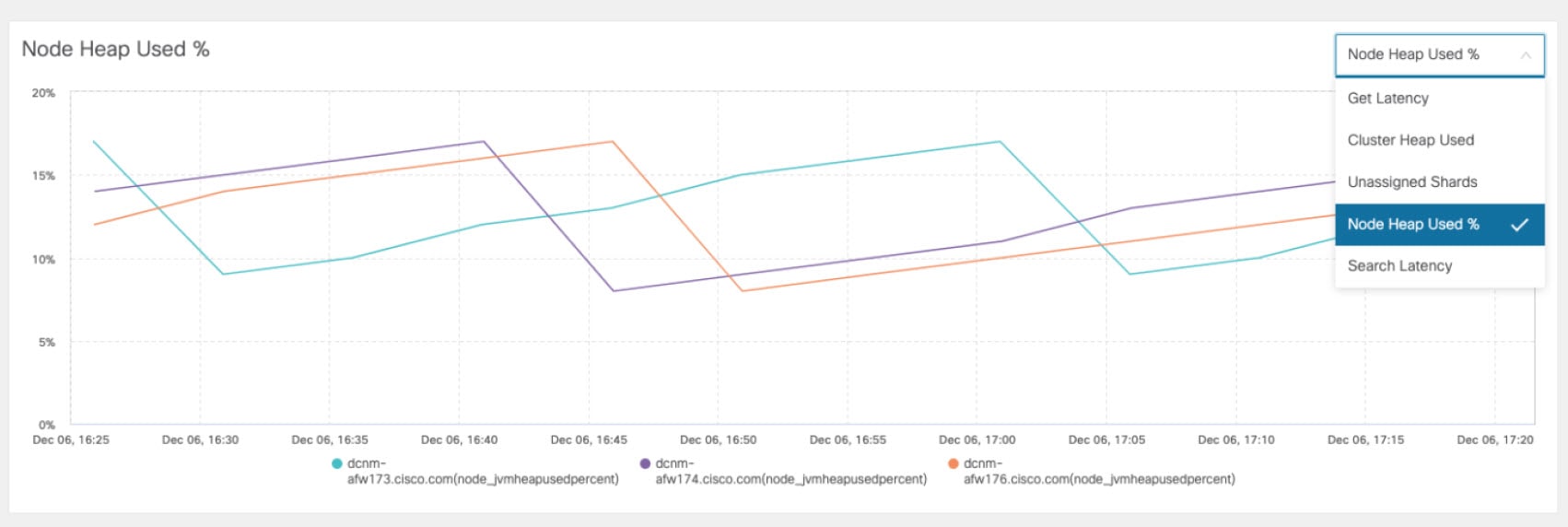
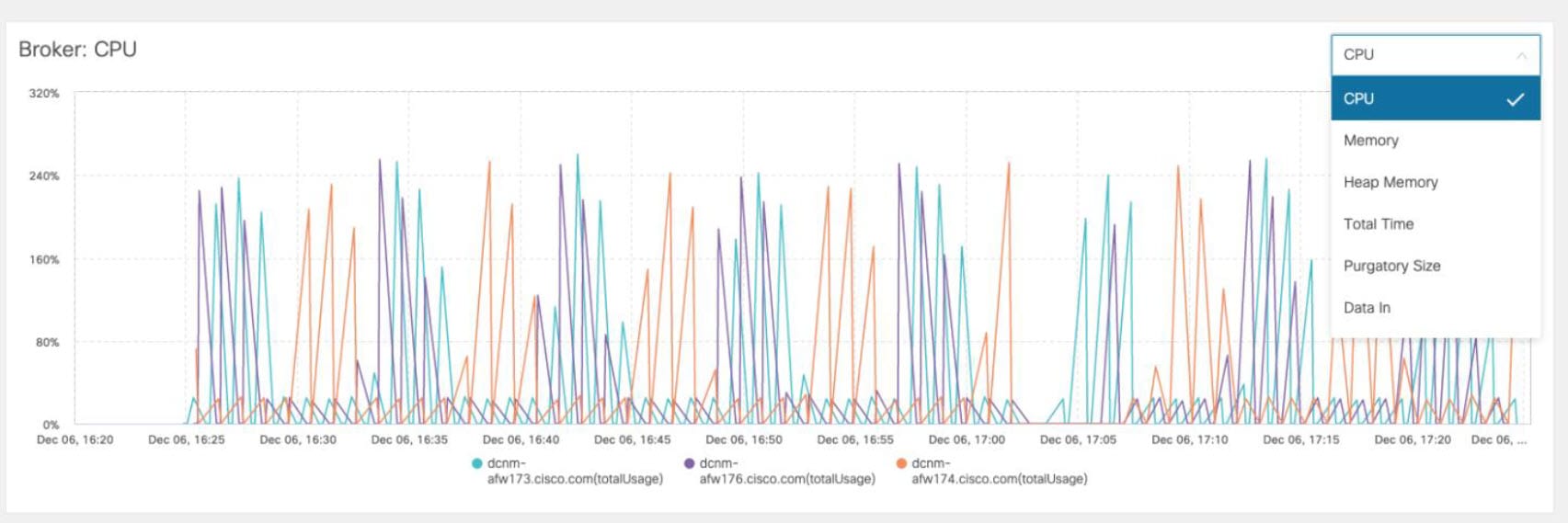
Health Monitor(2.0)



 Feedback
Feedback