Deployment Overview
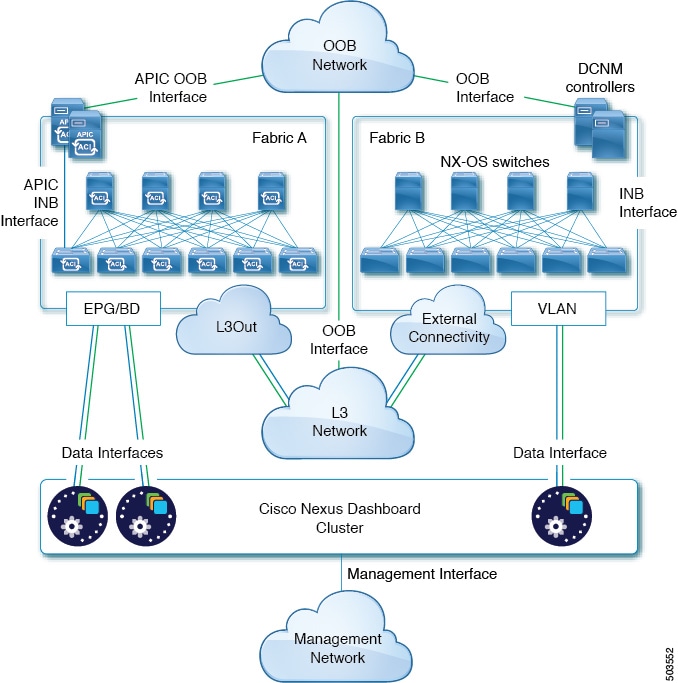
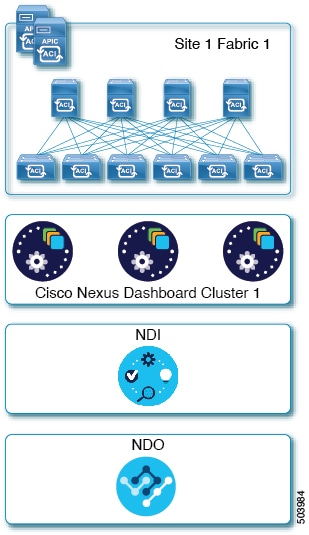
Cisco Nexus Dashboard is a central management console for multiple data center sites and a common platform for hosting Cisco data center operation services, such as Nexus Dashboard Insights and Nexus Dashboard Orchestrator. These services are available for all the data center sites and provide real time analytics, visibility, assurance for network policies and operations, as well as policy orchestration for the data center fabrics, such as Cisco ACI or Cisco NDFC.
Nexus Dashboard provides a common platform and modern technology stack for the above-mentioned micro-services-based applications, simplifying the life cycle management of the different modern applications and reducing the operational overhead to run and maintain these applications. It also provides a central integration point for external 3rd party applications with the locally hosted applications.
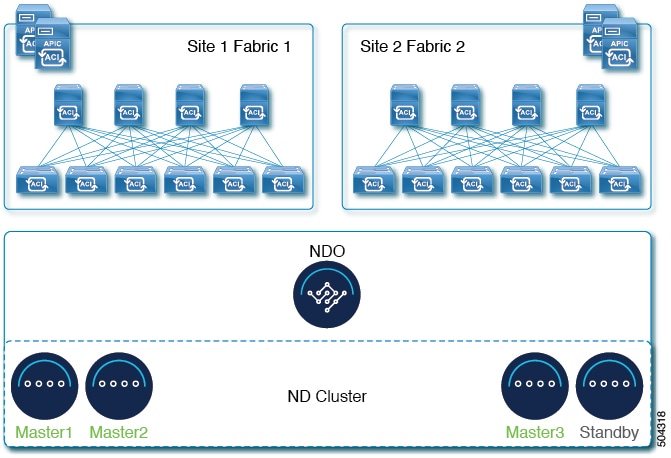
Each Nexus Dashboard cluster typically consists of 3 master nodes. In addition, you can provision a number of worker nodes to enable horizontal scaling and standby nodes for easy cluster recovery in case of a master node failure. For maximum number of worker and standby nodes supported in this release, see the "Verified Scalability Limits" sections of the Cisco Nexus Dashboard Release Notes.
 Note |
This document describes initial configuration of the 3-node cluster. After your cluster is up and running, you can configure and deploy additional nodes as described in the Cisco Nexus Dashboard User Guide, which is also available directly from the Nexus Dashboard GUI. |
Hardware vs Software Stack
Nexus Dashboard is offered as a cluster of specialized Cisco UCS servers (Nexus Dashboard platform) with the software framework (Nexus Dashboard) pre-installed on it. The Cisco Nexus Dashboard software stack can be decoupled from the hardware and deployed in a number of virtual form factors. For the purposes of this document, we will use "Nexus Dashboard platform" specifically to refer to the hardware and "Nexus Dashboard" to refer to the software stack and the GUI console.
This guide describes the initial deployment of the Nexus Dashboard software; hardware setup is described in the Nexus Dashboard Hardware Setup Guide, while other Nexus Dashboard operations procedures are described in the Cisco Nexus Dashboard User Guide.
Services
Nexus Dashboard is a standard appliance platform to build and deploy services that would allow you to consume all Nexus Dashboard products in a consistent and uniform manner. You can subscribe and consume services like Insights, Orchestrator, Fabric Controller, and Data Broker with the Nexus Dashboard platform providing the necessary capacity and life cycle management operations for these services.
Typically, the Nexus Dashboard platform is shipped with only the software required for managing the lifecycle of these services, but no actual services are packaged with the appliance. If you allow public network connectivity from your data centers, you can download and install the services with a few clicks. However, without public network connectivity, you will need to manually download these services, upload them to the platform, and perform installation operations before you can use them.
Beginning with Release 2.1(2), if you are ordering the physical Nexus Dashboard servers, you have the option to choose Nexus Dashboard Insights and Nexus Dashboard Orchestrator services to be pre-installed on the hardware before it is shipped to you. For more information, see the Nexus Dashboard Ordering Guide. Note that if you are deploying the virtual or cloud form factors of the Nexus Dashboard, there are no changes to service installation and you will need to deploy the services separately after the cluster is ready.
Available Form Factors
This release of Cisco Nexus Dashboard can be deployed using a number of different form factors. Keep in mind however, you must use the same form factor for all nodes, mixing different form factors within the same cluster is not supported.
-
Cisco Nexus Dashboard physical appliance (
.iso)This form factor refers to the original physical appliance hardware that you purchased with the Cisco Nexus Dashboard software stack pre-installed on it.
The later sections in this document describe how to configure the software stack on the existing physical appliance hardware to deploy the cluster. Setting up the original Cisco Nexus Dashboard platform hardware is described in Cisco Nexus Dashboard Hardware Setup Guide.
-
VMware ESX (
.ova)Virtual form factor that allows you to deploy a Nexus Dashboard cluster using three VMware ESX virtual machines.
-
Linux KVM (
.qcow2)Virtual form factor that allows you to deploy a Nexus Dashboard cluster using three Linux KVM virtual machines.
-
Amazon Web Services (
.ami)Cloud form factor that allows you to deploy a Nexus Dashboard cluster using three AWS instances.
-
Microsoft Azure (
.arm)Cloud form factor that allows you to deploy a Nexus Dashboard cluster using three Azure instances.
Upgrading From Previous Versions of Nexus Dashboard
If you are already running a Nexus Dashboard, Release 2.0.1 or later, you can upgrade directly to the latest release while retaining the cluster configuration and applications, as described in Upgrading Nexus Dashboard
Upgrading From Application Services Engine
If you are running Cisco Application Services Engine, you must upgrade to Nexus Dashboard release 2.0.2g or later as described in Cisco Nexus Dashboard Deployment Guide, Release 2.0(x) before upgrading to Nexus Dashboard release 2.1.x.
Cluster Sizing Guidelines
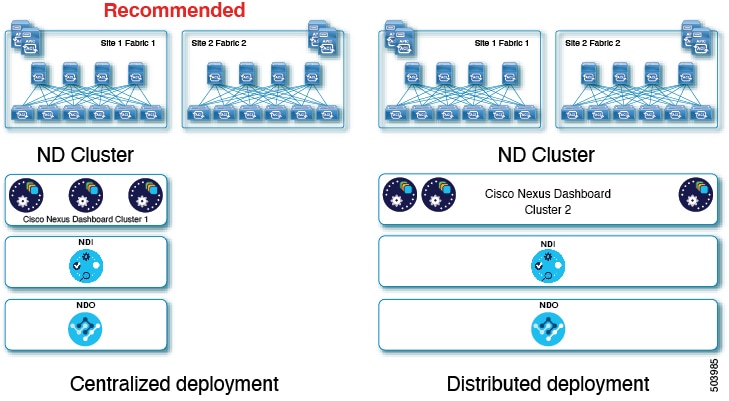
Nexus Dashboard supports co-hosting of applications. Depending on the type and number of applications you choose to run, you may be required to deploy additional worker nodes in your cluster. For cluster sizing information and recommended number of nodes based on specific use cases, see Cisco Nexus Dashboard Cluster Sizing.
After your initial 3-node cluster is up and running, you can configure and deploy additional nodes as described in the Cisco Nexus Dashboard User Guide, which is also available directly from the Nexus Dashboard GUI.
Supported Services
For the full list of supported applications and the associated compatibility and interoperability information, see the Nexus Dashboard and Services Compatibility Matrix.
 Feedback
Feedback